
Data Science Project: NGSS Analysis
Summary
The study considers how to prioritize the content knowledge development of secondary (6-12) science teachers through the analysis of two dimensions of the NGSS. The results demonstrate that high priority cross-cutting concepts (CCCs) and science and engineering practices (SEPs) might allow the trainers of science teachers to focus their efforts on a select set of content. Additionally, several relationships between specific SEPs and CCCs are found to increase the specificity of the coursework.
Introduction
So here’s the challenge: we need to support the development of teachers’ science content knowledge as they gain their Master’s of Arts in Teaching. But not every teacher begins their degree with the same baseline of knowledge. This is in addition to the fact that they are not all teaching classes that leverage their formal science educations. Oh, and they are teaching content from a multitude of disciplines and across all grade levels. And - to top it off - they are also trying to learn about all the other aspects of teaching at the same time!
One solution is to focus our teachers’ content knowledge development through the Next Generation Science Standards (NGSS). The NGSS are a framework for teaching K-12 science in a three-dimensional manner: content, practices, and cross-cuttting concepts. The NGSS have been widely adopted in the United States, which is great because the NGSS represent a much more progressive approach to science education (i.e., not just memorizing science facts). Using the NGSS also means that we can focus on the cross-cutting concepts (CCCs) - seven concepts that universally applicable across all science domains (and, I would argue, across all subjects!).
However, we cannot realistically cover all the of the CCCs at an appropriate level of depth while providing a coherent and cohesive experience for our teachers. So we need to prioritize. But, which CCCs are the most important? Or are they all equally important? And if we choose specific CCCs to focus on, are they connected to specific science and engineering practices (SEPs)? Let’s boil these wonderings down into a couple research questions:
Research Questions
- How are the CCCs and SEPs represented in the NGSS? Is there a difference between middle and high school?
- Is there a relationship between CCCs and SEPs?
Methodology
The NGSS organizes the content, SEPs, and CCCs into statements called performance expectations (PEs) which are freely available on the Internet. However, there are 208 of them, which would mean that taking the time to go to each webpage to figure out which SEPs and CCCs are specific to a PE would take a whole lot of time. And be super repetitive. So it’s time for some webscraping!
Gathering Data via Web Scraping
To create a data set of all the PEs, CCCs, and SEPs, I started with some light investigation of the official NGSS website. I found that you could search for the PEs, or download a full PDF of the standards. You can also access the individual pages for each PE, if you know the number and the full name. I don’t know all 208 PEs, so I looked for another route.
Given my familiarty with science education, I quickly realized that the National Science Teaching Association might have a better solution. And they do! They have created id numbers for each PE page, which means that I could easily set up a web scraper using BeautifulSoup and request after using a loop to gather all the appropriate URLs. The resulting data was then saved to a pandas DataFrame:
from bs4 import BeautifulSoup
import requests
import pandas as pd
#Create empty list to gather site links
urls = []
#Append all links to urls list
for i in [x for x in range(23,234) if x != 24 and x != 25 and x!=201]:
urls.append('https://ngss.nsta.org/DisplayStandard.aspx?view=pe&id=' + str(i))
#Create empty lists
pe_num_list = []
sep_list = []
ccc_list = []
#Loop through all pages
for url in urls:
source = requests.get(url).text
soup = BeautifulSoup(source, 'lxml')
try:
#Get the performance expectation
pe_num = soup.select('.std > a')
#Convert the soup element to a string and only get text
pe_num = str(pe_num[0].getText())
#Append PE_num to appropriate list
pe_num_list.append(pe_num)
#Get the SEP
sep = soup.select('#MainContent_rptPractices_lblPractice_0')
#Convert the soup element to a string and only get text
sep = str(sep[0].getText())
#Append SEP to appropriate list
sep_list.append(sep)
#Get the crosscutting concept using the CSS selector
ccc = soup.select('#MainContent_rptConcepts_lblConcept_0')
#Convert the soup element to a string and only get text
ccc = str(ccc[0].getText())
#Append ccc to appropriate list
ccc_list.append(ccc)
except IndexError:
ccc_list.append("None")
continue
#Create dataframe with NGSS dictionary
ngss_df = pd.DataFrame(
{"PE_Number": pe_num_list,
"SEP": sep_list,
"CCC": ccc_list
})
DataFrame Manipulation with pandas
With the data collected, I created a Jupyter notebook and used pandas to reformat and group the data to be more readable. In particular, I needed to separate the grade level/band from the PE and group all the elementary grades together into one “K-5” band:
#Import pandas module
import pandas as pd
#Import matplotlib
import matplotlib.pyplot as plt
#Ask user which file they want to access
filename = 'ngss.csv'
#Create variable using pandas to read the file
df = pd.read_csv(filename)
# Create a new data frame with split value columns
new = df["PE_Number"].str.split("-", n=1, expand=True)
# Making a separate grade column from new data frame
df["Grade"]= new[0]
# Making a separate PE column from new data frame
df["PE"]= new[1]
# Drop the old PE_Number columns
df.drop(columns =["PE_Number"], inplace = True)
# Add a column for grade bands
grade_bands = []
for grade in df.Grade:
if grade == "K" or grade == "1" or grade == "2" or grade == "3" or grade == "4" or grade == "5":
grade_bands.append("K-5")
else:
grade_bands.append(grade)
df["Grade_Bands"] = grade_bands
#Drop the Grade column as the grade bands is only needed
df.drop(columns =["Grade"], inplace = True)
To compare the three grade bands - elementary, middle, and high school - I needed to select specific rows from the data frame. I could also then filter out the elementary grade band as I am currently more focused on middle and high school.
#Set index to Grade_bands to utilize .loc
df = df.set_index("Grade_Bands")
# Determine and plot the frequency of each cross-cutting concept
ccc_freq = df['CCC'].value_counts(normalize=True) *100
#Determine CCC breakdown in HS
hs = df.loc["HS"]
hs_freq = hs['CCC'].value_counts(normalize=True) *100
#Determine CCC breakdown in MS
ms = df.loc["MS"]
ms_freq = ms['CCC'].value_counts(normalize=True) *100
#Determine CCC breakdown in MS
k5 = df.loc["K-5"]
k5_freq = k5['CCC'].value_counts(normalize=True) *100
#Combine series into one dataframe
all_ccc = pd.concat([k5_freq, ms_freq, hs_freq, ccc_freq], axis=1)
all_ccc.columns = ["K-5_CCC", "MS_CCC", "HS_CCC", "All_CCC"]
#Only view secondary CCC
sec_ccc = all_ccc[["MS_CCC", "HS_CCC"]]
sec_ccc
I went through a similar process for the SEPs - the full code and the resulting .csv file can be found on my GitHub.
The last step was to manipulate the MS and HS dataframes to see if there was a relationship between SEPs and CCCs. This was accomplished by grouping the CCCs and the SEPs using the .count method:
#Count the number of times a CCC is connected a SEP - MS
ms_group = ms.groupby(["CCC","SEP"]).count()
#Sort the values in descending order - MS
ms_group_srt = ms_group.sort_values(["PE","SEP"], ascending = False)
#Count the number of times a CCC is connected a SEP - HS
hs_group = hs.groupby(["CCC","SEP"]).count()
#Sort the values in descending order - HS
hs_group_srt = hs_group.sort_values(["PE","SEP"], ascending = False)
Results
RQ #1: The cross-cutting concepts are not represented equally
The data gathering and analysis demonstrated that certain CCCs are represented far more often in the NGSS performance expectations:
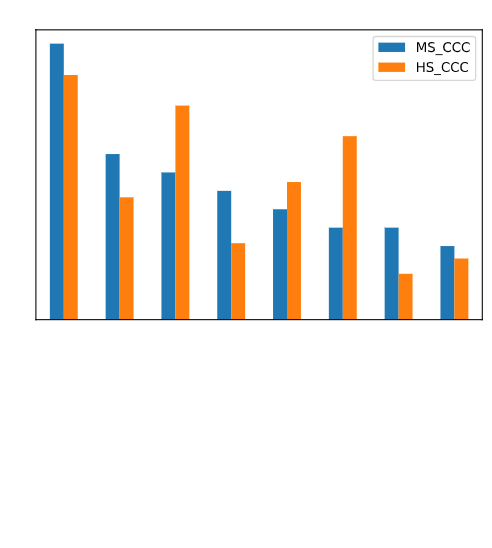
In particular, the CCC “Cause and Effect” has the greatest representation in both middle and high school PEs (25% of PEs in middle school and 23% of PEs in high school). The CCCs “Energy and Matter” (14% MS; 20% HS) and “Patterns” (15% MS; 11% HS) are also well represented in comparison to the remaining four CCCs.
The SEPs are also not represented equally:
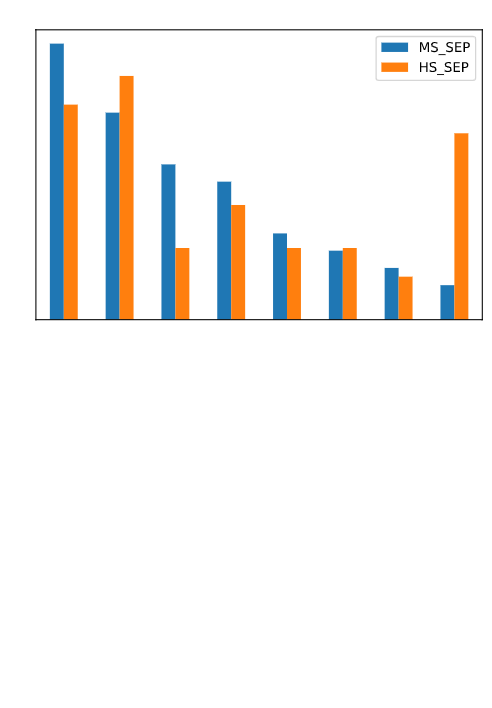
The SEP “Developing and Using Models” accounts for 27% of middle school PEs and 21% of high school PEs. The SEPs “Constructing Explanations and Designing Solutions” (20% MS; 24% HS) and “Engaging in Argument from Evidence” (14% MS; 11% HS) are also well represented in comparison to the remaining five SEPs.
RQ #2: There are limited relationships between the cross-cutting concepts and science and engineering practices
The grouping of the SEPs and CCCs in each of the secondary grade bands demonstrated that relationships do appear to exist, but only for a select set of pairings and at a limited level.
At the middle school level, the CCC “Patterns” and the SEP “Analyzing and Interpreting Data” are most frequently paired together in PEs. The table below shows the other CCCs and SEPs that appear together in at least three PEs:

At the high school level, the CCC “Energy and Matter” and the SEP “Developing and Using Models” are paired together in seven PEs. The table below shows the other CCCs and SEPs that appear together in at least three PEs:

Conclusions
Determining the right focus for content knowledge development for science teachers can be challenging, especially when working with teachers who span domains and grade levels. However, this study has shown that there are ways to prioritize content in the form of CCCs and SEPs.
In particular, the results demonstrate that three of the seven CCCs account for the majority of the PEs in both MS and HS. If teachers could develop their knowledge of “Cause and Effect,” “Patterns,” and “Energy and Matter,” they would be well prepared to engage with approximately 53% of MS PEs and 54% of HS PEs. Additionally, if the focus for content knowledge could be focused on three of the eight SEPs (“Developing and Using Models,” “Constructing Explanations and Designing Solutions,” and “Engaging in Argument from Evidence”), teachers would be ready to engage with approximately 61% of MS PEs and 56% of HS PEs.
Given the frequency of a select group of CCCs and SEPs in the NGSS PEs, it is not surprising that these SEPs and CCCs tend to be paired together. In particular, it would be prudent to focus on teaching PEs that feature “Energy and Matter” with “Developing and Using Models” or “Cause and Effect” with “Constructing Explanations and Designing Solutions.”
Teachers have a limited amount of time and cognitive space to give to content knowledge development. Prioritizing content based on patterns in how the NGSS PEs are designed can ensure that teachers are leveraging their time in the most meaningful way possible.
Potential Next Steps
While this study considered the relationship between SEPs and CCCs at a high level, further analysis could be done for indiciators within the grade-level progressions (see, for example, “Asking and Defining and Problems”).
Additionally, the third dimension of the NGSS - the displinary core ideas (DCIs) - was not considered in this study. Further analysis considering relationships between the SEPs, CCCs and the DCIs could be completed to consider which core ideas should be the focus of science teacher training.
Finally, this data science project utilized a variety of tools and scripts. Refactoring could be done to increase the efficiency and transferability of the code.